
Research Highlight
- 자기부상 기반 지상 모사 비행시험 및 강화학습을 통해 스스로 학습하는 지능형 비행체 개발 (한재흥 교수님 연구실) -
이번 Research Highlight에서는 2020년 11월에 한국항공우주산업 (KAI) 주관의 KAI 항공우주논문상에서 최우수상을 (산업부 장관상) 수상한 성열훈 박사과정의 (한재흥 교수님 연구실) “자기부상 기반 지상 모사 비행시험 및 강화학습을 통해 스스로 학습하는 지능형 비행체 개발”를 소개하도록 하겠습니다.
강화학습은 학습 대상인 에이전트가 주변 환경과 상호작용하는 과정에서 시행착오를 통해 보상을 최대화하는 정책을 학습하는 기계학습의 일종으로, 일반인들에게도 알파고와 같은 대표적인 응용 사례들이 알려질 정도로 유망한 인공지능 기법이다. 강화학습은 특별한 지도나 사전 지식 없이도 비행체 스스로 주어진 문제를 해결하는 정책을 학습할 수 있으며, 종종 인간보다 뛰어난 성능을 보이곤 한다는 점에서 지능형 제어 시스템 개발을 위한 핵심적인 방법으로 대두되고 있다.
하지만 강화학습 과정에서 비행체는 추락을 야기할 수 있는 위험한 행동을 시도할 수 있기 때문에, 시행착오에 기반한 이 학습 방법을 실제 기체에 직접 적용하기는 어렵다는 한계가 존재한다. 이에 따라 가상 환경에서 시뮬레이션 기반의 학습이 주로 시도되고 있으나, 실제 기체 및 그 비행 환경을 정확히 모델링 하는 것은 불가능하기 때문에 가상 환경에서 학습된 정책이 실제 환경에서는 목표한 성능을 내지 못하곤 한다.
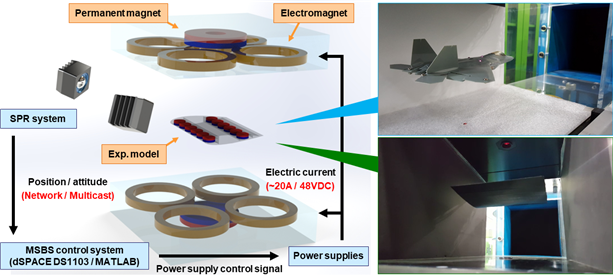
<그림 1> KAIST 스마트 구조 및 하드웨어 시스템 연구실에서 자체 개발한 자기부상 풍동 개요도
본 논문에서는 비행체가 추락 및 파손 위험 없이, 스스로 최적의 비행 제어 정책을 찾는 방법을 제시한다. <그림 1>과 같이 자기부상 원리에 기반하여 초소형 비행체를 공중 부양하고, 위치 및 자세를 기계적인 접촉 없이 넓은 영역에서 제어할 수 있는 자기부상장치를 개발하였으며, 더 나아가 기체에 작용하는 자기력을 제어하여 자유 비행 상태를 모사함과 동시에, 기체의 안전을 보장할 수 있는 비행시험 환경을 개발하였다. 이 환경은 초소형 비행체의 실제 비행 상황을 모사하면서도, 시행착오 과정에서 위험한 행동을 시도하더라도 기체의 안전을 보장할 수 있다는 점에서 실물 기반의 강화학습을 가능하게 한다.
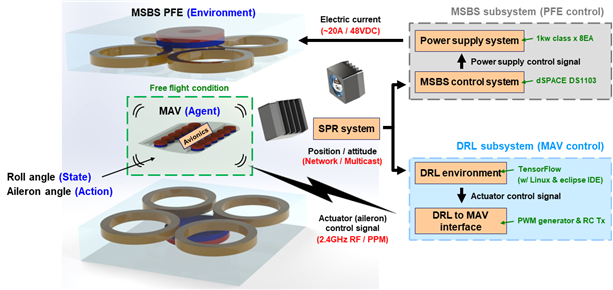
<그림 2> 자기부상 기반 지상 모사 비행시험 및 강화학습을 통해 스스로 학습하는 비행체 개발을 위한 실험 장치 개요도
<그림 2>는 스스로 비행 방법을 학습하는 비행체 개발을 위한 실험 장치 구성 개요도로, 상술한 자기부상 기반 지상 모사 비행시험 환경과 비행체 자가 학습 시스템으로 구성되어있다. 비행체 자가 학습 시스템은 <그림 3>과 같이 강화학습에 인공신경망 기반의 심층학습이 결합된 심층 강화학습을 기반으로 개발되었으며, 연속적인 상태 공간 및 행동 공간을 갖는 문제 해결에 우수한 성능을 보이는 것으로 알려진 Proximal Policy Optimization (PPO) 알고리즘을 적용하였다. 이를 통해 공중 부양된 초소형 비행체는 관측된 상태를 기반으로 수행할 행동을 실시간으로 결정하며, 그 결과로 받는 보상을 최대화 하기 위한 인공신경망 기반 정책을 학습한다.

<그림 3> 심층 강화학습 기반의 비행체 자가 학습 시스템

<그림 4> 자기부상 기반 지상 모사 비행시험 및 강화학습을 통해 스스로 학습하는 비행체 개발을 위한 실험 장치
<그림 4>와 같이 최종 구성된 실험 장치를 이용하여, 롤 자세각 제어를 위해 한 쌍의 에일러론을 구동하는 방법을 스스로 학습하는 초소형 비행체를 시연하였다. 비행 상태를 모사하기 위해 풍동 시험을 수행하는 동안 공중 부양된 초소형 비행체의 에일러론 각도가 변화하면, 작용하는 공력에 의해 롤 자세가 변화하게 된다. 이로부터 수행한 행동이 롤 자세각 제어를 위해 바람직하였는지 여부를 보상의 형태로 평가받게 되며, 목표로 하는 자세각에 가까울수록 높은 보상을 획득하도록 설계하였다.
한편 이러한 시행착오 기반 학습이 수행되는 동안 불안정을 야기하는 위험한 행동을 시도하여 특정 롤 각도 이상으로 기체 자세각이 변화하게 되면, 기체의 움직임에 반대되는 방향으로 자기모멘트를 생성하여 더 이상의 발산을 방지하여 기체의 추락을 방지하게 된다.

<그림 5> 자기부상 기반 지상 모사 비행시험을 통해 스스로 롤 제어 방법을 학습하는 비행체: (a-d) 학습 중, (e-h) 학습 후
이러한 과정을 통해 <그림 5>와 같이 초소형 비행체 실물 모델은 개발된 비행시험 환경과 상호작용하는 과정에서, 시행착오를 통해 주어진 제어 목표 (시계방향 3deg) 달성을 위한 최적 정책을 스스로 학습할 수 있음을 시연하였다. 이 때, <그림 5 (a-d)>와 같이 다양한 시도를 하며 학습이 진행되는 동안에도, <그림 6 (좌)>와 같이 기체의 롤 자세각이 사전 설정된 각도 이상으로 변화하지 못하도록 자기모멘트가 작용함으로써 기체의 안전이 보장되는 지상 모사 비행시험이 가능함을 볼 수 있다. 이를 통해 기체 및 비행 환경을 가상 환경으로 모델링 하는 과정에서 발생하는 오류를 배제하여, 실제 기체 및 구동기의 동특성이 반영된 정책을 학습하는 것이 가능하다.
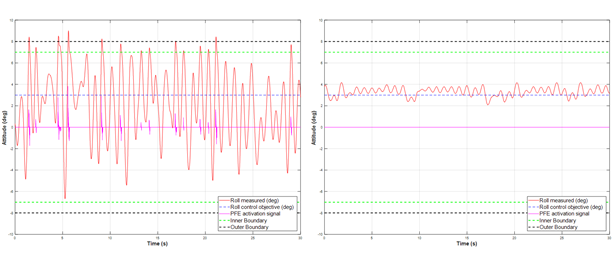
<그림 6> 자기부상 기반 지상 모사 비행시험을 통해 스스로 롤 제어 방법을 학습하는 비행체: (좌) 학습 중의 롤 자세각 변화, (우) 학습 후의 롤 자세각 변화
![]()
원고 성열훈[iguana2@kaist.ac.kr]
편집 박진우[jinpark57@kaist.ac.kr]
Comment 0
- Total
- 56호
- 55호
- 54호
- 53호
- 52호
- 51호
- 50호
- 49호
- 48호
- 47호
- 46호
- 45호
- 44호
- 43호
- 42호
- 41호
- 40호
- 39호
- 38호
- 37호
- 36호
- 35호
- 34호
- 33호
- 32호
- 31호
- 30호
- 29호
- 28호
- 27호
- 26호
- 25호
- 24호
- 23호
- 22호
- 21호
| No. | Subject |
|---|---|
| Notice | 자유기고 모집 |
| Notice | Fund Raising |
| 344 |
항공우주공학과 News
|
| 343 |
신규 사업 소개 (복합 화학반응을 포함한 극초음속 다원자 혼합물 유동의 입자기반 해석기법 개발)
|
| 342 |
연구실 탐방 (전기추진 및 이온빔 응용 연구실 연구실)
|
| 341 |
연구실 탐방 (Space Testing And Research 연구실)
|
| 340 |
학부생 소식 (2025 봄 해피아워 개최)
|
| 339 |
특집 인터뷰 (이동호 교수)
|
| 338 |
동문 인터뷰 (Caltech 연구원 서종은 박사)
|
| 337 |
Research Highlight (이상봉 교수)
|
| 336 |
항공우주 이야기 (민간 무인 탐사선 블루 고스트 달 착륙)
|
| 335 |
Photo Album
|
| 334 |
항공우주공학과 News
|
| 333 |
연구실 탐방 (익스트림역학 및 멀티피직스 연구실)
|